部署
使用ceph-deploy按照官网文档,一步一步的可以轻松部署一个的集群。注意如果集群规模节点很多时,可以写一些shell脚本避免重复的执行OSD创建的命令。本节不再详细描述部署步骤部分,重点描述一下集群部署完成后Pool的副本分布设置技巧。
怎样设置副本分布到不同的机架
对象映射到OSD过程简述
Ceph中Pools的属性有:
- Object的副本数
- Placement Groups的数量
- 所使用的CRUSH Ruleset
在Ceph中,Object先映射到PG,再由PG映射到OSD set。每个Pool有多个PG,每个Object通过计算hash值并取模得到它所对应的PG。PG再映射到一组OSD(OSD的个数由Pool 的副本数决定),第一个OSD是Primary,剩下的都是Replicas。
数据映射的方式决定了存储系统的性能和扩展性。PG到OSD set的映射由四个因素决定:
- CRUSH算法:一种伪随机算法。
- OSD MAP:包含当前所有Pool的状态和所有OSD的状态。
- CRUSH MAP:包含当前磁盘、服务器、机架的层级结构。
- CRUSH Rules:数据映射的策略。这些策略可以灵活的设置object存放的区域。比如可以指定 pool1中所有objecst放置在机架1上,所有objects的第1个副本放置在机架1上的服务器A上,第2个副本分布在机架1上的服务器B上。 pool2中所有的object分布在机架2、3、4上,所有Object的第1个副本分布在机架2的服务器上,第2个副本分布在机架3的服 器上,第3个副本分布在机架4的服务器上。

Client从Monitors中得到CRUSH MAP、OSD MAP、CRUSH Ruleset,然后使用CRUSH算法计算出Object所在的OSD set。所以Ceph不需要Name服务器,Client直接和OSD进行通信。伪代码如下所示:
obj_hash = hash(object_name)
pg = obj_hash % num_pg
osds = crush(pg, crushmap, osdmap, ruleset) # returns a list of osds for pg
primary = osds[0]
replicas = osds[1:]
编辑CRUSH Map
以YY云平台为例:
集群中包括3个机架,每个机架有7个主机,每个主机有12个OSD。
bucket有4种: root、row、rack、host,包含关系如下:
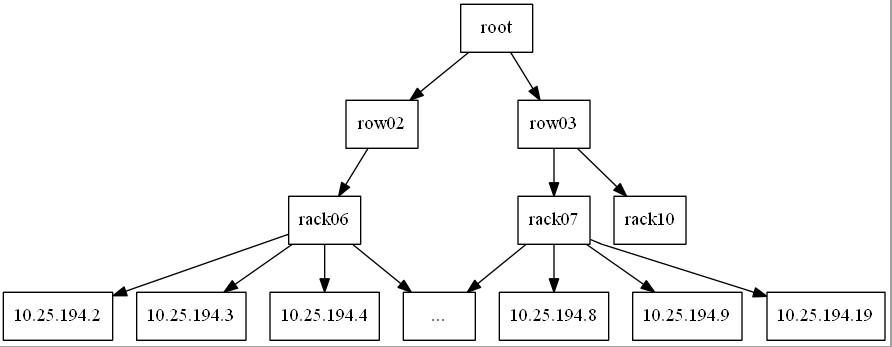
下面命令过程以把 ip-10-25-194-2 为例重新设置此Host在CRUSH Map中的位置,可以仿此逐步完成每个Host的编辑,如果你觉得麻烦也可以像我们一样通过脚本工具完成这个过程。 你也可以参考下节直接编辑CRUSHMAP的文本文件进行重新设定,这也是一个比较快捷的方法。
ceph osd crush add-bucket 02 row
ceph osd crush move 02 root=default
ceph osd crush add-bucket 02-06 rack
ceph osd crush move 02-06 row=02
sudo ceph osd crush move ip-10-25-194-2 rack=02-06
工具代码参考:
cat<<'EOF'> gen_crushmap.py
#!/bin/python
#row 每行的格式为ip row-rack
rows = '''
10.25.194.22 03-07
10.25.194.20 03-10
10.25.194.2 02-06
'''
hosts = []
racks = set()
rows = set()
for l in rows.splitlines():
import re
ary = re.split('\s+', l)
#ip to hostname like ip-10.25.194.22
if len(ary) == 2:
hosts.append([ary[0].replace('.', '-'), ary[1]])
racks.add(ary[1])
rows.add(ary[1].split('-')[0])
for row in rows:
print "sudo ceph osd crush add-bucket %s row" % row
print "sudo ceph osd crush move %s root=default" % row
for rack in racks:
print "sudo ceph osd crush add-bucket %s rack" % rack
print "sudo ceph osd crush move %s row=%s" % (rack, rack.split('-')[0])
for ary in hosts:
print "sudo ceph osd crush move ip-%s rack=%s" %(ary[0], ary[1])
EOF
python gen_crushmap.py > crushmap.sh
sh crushmap.sh
>
增加一个按rack分布副本的RuleSet
你可以按照如下代码中的步骤,一步一步完成RuleSet的添加。
- 获取crushmap的二进制格式文**件
- 反编译crushmap的二进制格式文件到文本文件
- 添加RuleSet到crushmap的文本文件
- 编译crushmap文本文件到二进制格式
- 使用编译后crushmap的二进制格式重设CRUSH Map
工具代码参考:
cat<<EOF>ruleset.sh
#! /bin/bash
sudo ceph osd getcrushmap -o crushmap.txt
crushtool -d crushmap.txt -o crushmap-decompile
# 增加副本分布于每个子架的规则集rack_replicated_ruleset
cat<<XXX>>crushmap-decompile
rule rack_replicated_ruleset {
ruleset 1
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type rack
step emit
}
XXX
crushtool -c crushmap-decompile -o crushmap-compiled
sudo ceph osd setcrushmap -i crushmap-compiled
EOF
sh ruleset.sh
如上工具创建了名为rack_replicated_ruleset的RuleSet,代码中step chooseleaf firstn 0 type rack 把默认的host改为rack, 表示CRUSH算法在选取副本过程中,先获取到一个有副本数个rack的List [03-07,03-10,02-06],然后再分别从每个rack中的host获取一个OSD,这样就能把副本分布不同的机架上。
创建Pool
创建Pool时指定RuleSet为rack_replicated_ruleset即可;
命令如下:
ceph osd pool create mypool 16384 rack_replicated_ruleset
测试PG副本在机架分布
命令和响应如下:
ceph osd map mypool myobject
osdmap e3934 pool 'rbd' (4) object 'myobject' -> pg 4.5da41c62 (4.c62) -> up ([24,159,38], p24) acting ([24,159,38], p24)
根据OSD [24,159,38]和这些OSD在OSD tree中的位置,可以确定PG已经分布到了不同的rack,这避免了单个rack或rack的TOR故障导致的ceph集群不可用,提高了集群可靠性